
 |

|
| ActiveWin: Reviews | Active Network | New Reviews | Old Reviews | Interviews |Mailing List | Forums |
|
|
|
|
|
DirectX |
|
ActiveMac |
|
Downloads |
|
Forums |
|
Interviews |
|
News |
|
MS Games & Hardware |
|
Reviews |
|
Support Center |
|
Windows 2000 |
|
Windows Me |
|
Windows Server 2003 |
|
Windows Vista |
|
Windows XP |
|
|
|
|
|
|
|
News Centers |
|
Windows/Microsoft |
|
DVD |
|
Apple/Mac |
|
Xbox |
|
News Search |
|
|
|
|
|
|
|
ActiveXBox |
|
Xbox News |
|
Box Shots |
|
Inside The Xbox |
|
Released Titles |
|
Announced Titles |
|
Screenshots/Videos |
|
History Of The Xbox |
|
Links |
|
Forum |
|
FAQ |
|
|
|
|
|
|
|
Windows XP |
|
Introduction |
|
System Requirements |
|
Home Features |
|
Pro Features |
|
Upgrade Checklists |
|
History |
|
FAQ |
|
Links |
|
TopTechTips |
|
|
|
|
|
|
|
FAQ's |
|
Windows Vista |
|
Windows 98/98 SE |
|
Windows 2000 |
|
Windows Me |
|
Windows Server 2002 |
|
Windows "Whistler" XP |
|
Windows CE |
|
Internet Explorer 6 |
|
Internet Explorer 5 |
|
Xbox |
|
Xbox 360 |
|
DirectX |
|
DVD's |
|
|
|
|
|
|
|
TopTechTips |
|
Registry Tips |
|
Windows 95/98 |
|
Windows 2000 |
|
Internet Explorer 5 |
|
Program Tips |
|
Easter Eggs |
|
Hardware |
|
DVD |
|
|
|
|
|
|
|
ActiveDVD |
|
DVD News |
|
DVD Forum |
|
Glossary |
|
Tips |
|
Articles |
|
Reviews |
|
News Archive |
|
Links |
|
Drivers |
|
|
|
|
|
|
|
Latest Reviews |
|
Xbox/Games |
|
Fallout 3 |
|
|
|
Applications |
|
Windows Server 2008 R2 |
|
Windows 7 |
|
|
|
Hardware |
|
iPod Touch 32GB |
|
|
|
|
|
|
|
Latest Interviews |
|
Steve Ballmer |
|
Jim Allchin |
|
|
|
|
|
|
|
Site News/Info |
|
About This Site |
|
Affiliates |
|
Contact Us |
|
Default Home Page |
|
Link To Us |
|
Links |
|
News Archive |
|
Site Search |
|
Awards |
|
|
|
|
|
|
|
Credits |


|
Product: GeForce 4 Ti 4600 Company: NVIDIA Website: http://www.nvidia.com Estimated Street Price: $399.99 Review By: Julien Jay |
GeForce Ti 4600 GPU
| Table Of Contents |
| 1:
Introduction 2: GeForce4 Ti 4600 Technology Explanation 3: GeForce 4 Ti 4600 Technology Explanation 2 4: GeForce 4 Ti 4600 Technology Explanation 3 5: nView 6: Direct 3D Benchmarks 7: OpenGL Benchmarks 8: Conclusion |
Engraved in
-
-
Manufactured in TSMC's
-
GPU clocked at

-
Memory clocked at
-
- AGP 2x/4x
- nfiniteFX II engine
- Accuview Anti Aliasing
- Light Speed Memory Architecture II
- nView
The theoretical performances of the chip are as follow:
-
Vertices per Second:
-
Fill
Rate:
-
Fill
Rate:
-
Operations per Second:
-
Memory
Bandwidth:
-
Maximum
Memory:
The
GeForce

GeForce 4 Ti 4600 GPU Die
GeForce 4 Technology Explanation
LightSpeed Memory Architecture II
The new enhanced Light Speed Memory Architecture II is aimed to optimize the memory�s bandwidth for a better and more realistic gaming experience. This new architecture includes six unique technologies responding to the sweet names of �Crossbar Memory Controller�, �Quad Cache�, �Z-Occlusion�, �Lossless Z Compression�, �Auto Pre-Charge� and �Fast Z-Clear�.
CrossBar Memory Controller
Just like the GeForce
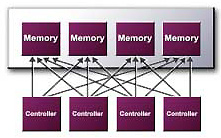
GeForce 4 Ti 4600 CrossBar
Memory Controller
Quad Cache
The Quad Cache is a brand new cache memory sub-system that regroups four distinct memory caches. Each of the four memory caches is dedicated to achieve a specific task: one is in charge of the primitives, one for the vertex, one for the texture, and one for the pixel. NVIDIA doesn�t disclose the size of each cache memory.
Once data has been processed by the GPU, a small quantity of data or the result of a calculation is stored in each cache with the enormous advantage to be instantly available for the GPU. Even if the GPU needs some of the information calculated before in order to render the next scene, it�ll retrieve this information from the quad cache rather than searching the whole memory to find back this data. We can detail the use of the Quad Cache like this:
-
Vertex Cache: This cache stores vertices after they are sent over the AGP bus. It makes the AGP more efficient by making sure there are no multiple transmissions of the same vertices.
-
Primitive Cache: This cache stores information issued from the operation that assembles vertices into fundamental primitives.
-
Dual Texture Cache: This feature was already present in the GeForce
-
Pixel Cache: Located at the end of the processing pipeline this cache is a coalescing cache. It waits for a certain quantity of pixels to be drawn before writing them to the memory using burst modes.
Auto Pre-Charge
Typically the information that is stored in a memory, no matter what kind of memory is being used, is always identically organized in banks. The problem of this architecture appears if the GPU needs to access information contained in another bank other than the one that is currently opened. To do so, the memory should close the bank actually used and then pre-charge and enable the new bank to give the GPU the information it needs. It results in a dramatic loss of performance since all the operations described above take ten clock cycles to complete while the GPU does nothing except wait.
GeForce
Fast Z-Clear
After each rendering of an image from a